Superquadrics are an extended set of quadric surfaces that can be
used to represent diverse shapes ranging from boxes, cylinders, and
ellipsoids to bi-cones, octahedra, and other complex symmetric shapes,
even those with rounded corners and edges. Superquadrics are further
categorized into superellipsoids, superhyperboloids, and supertoroids;
for our modeling purposes the superellipsoids are sufficient. The
corresponding implicit equations for a superquadric surface with size parameters
\((a_1, a_2, a_3) \in \mathbb{R}_+^3\) and shape parameters \((e_1, e_2) \in \mathbb{R}_+^2\)
are of the form: for \(\textbf{x} = (x, y, z)\),
$$
\begin{equation*}
f(\textbf{x})=\left(\left|\frac{x}{a_1}\right|^{\frac{2}{e_2}}
+ \left|\frac{y}{a_2}\right|^{\frac{2}{e_2}}\right)^{\frac{e_2}{e_1}}
+ \left|\frac{z}{a_3}\right|^{\frac{2}{e_1}} = 1.
\end{equation*}
$$
Although more expressive than quadrics, superquadrics are still limited
by their inability to capture tapered and bent objects. Deformable
superquadrics are obtained by applying global tapering and bending
deformations as shown below.
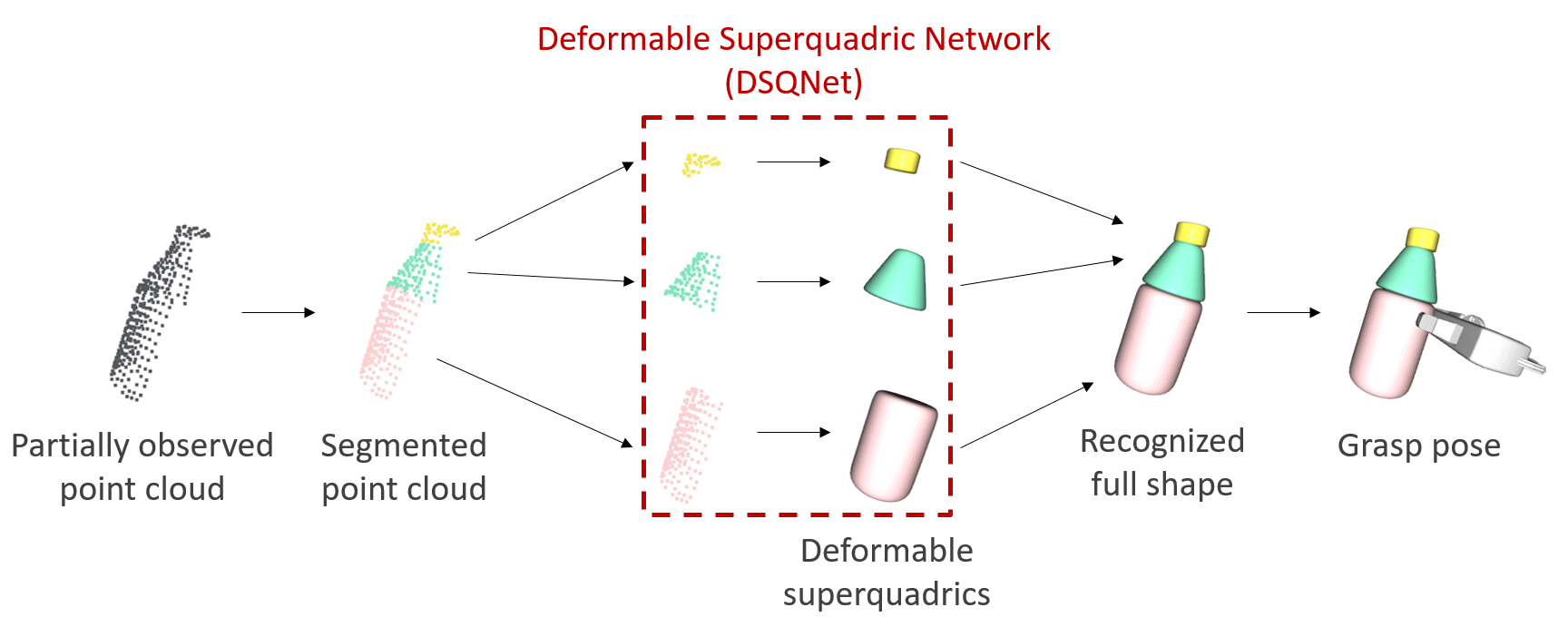
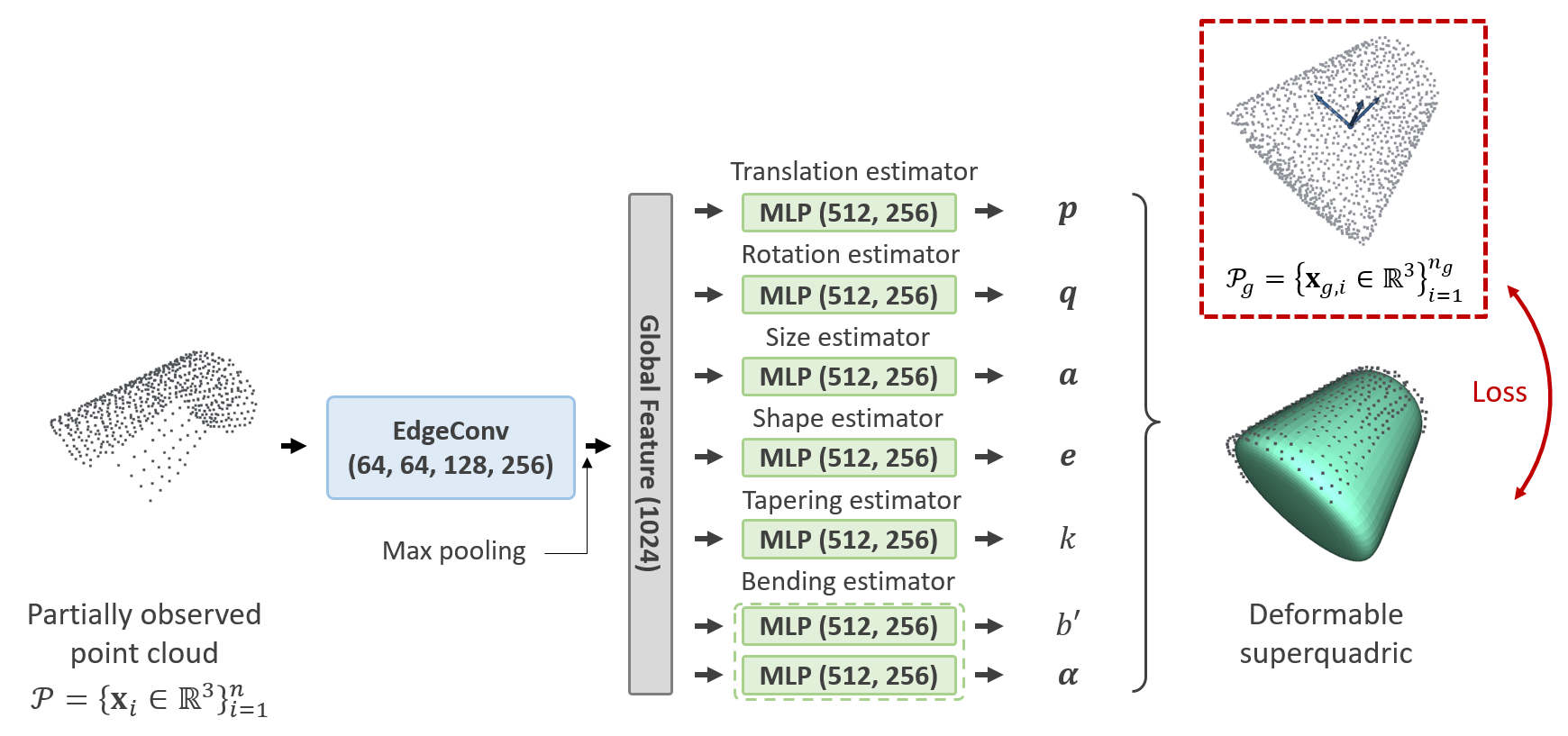
We design a neural network architecture, referred to as the Deformable Superquadric Network
(DSQNet), which takes partially observed point cloud data as input and outputs the eight
parameters and the pose of the deformable superquadric. This output aims to reconstruct the
full shape of the object, including its occluded parts. The network is trained to minimize
fitting errors between the ground-truth point cloud and the predicted deformable superquadric.
Recognition is achieved quickly and accurately with a simple forward pass through the neural network.
Extensive experiments and benchmark comparisons using a variety of everyday objects demonstrate both
the strengths of our approach and potential areas for improvement. For recognizing household objects,
our method achieves the highest accuracy (in terms of volumetric IoU) and the fastest computation speeds
among existing recognition-based methods.